|
LEVEL 2

- 积分
- 6
- 金币
- 298 枚
- 威望
- 0 点
- 金镑
- 0 个
- 银币
- 5 枚
- 舍利
- 0 枚
- 注册时间
- 2018-2-22
- 最后登录
- 2024-8-23
|
1楼
大 中
小 发表于 2019-2-21 23:32 显示全部帖子

抛砖引玉:几行python代码小爬一下第一会所
阅读了一下版规,没说不可以发爬虫,更没说不可以爬第一会所,哈哈哈。本来是想发一个教程主题帖来着,可是本身我的代码功能就很简单,只是个学习性的东西,而且现在已经挺晚了,要发详细教程的话估计弄到明天也弄不完,况且这个代码也是我很久之前照着别的网站的教程写的,具体我怎么分析的第一会所的HTML基本已经忘光了。所以就来抛砖引玉一下吧,网上爬虫的教程挺多的,主要是大家可以根据这个思路来开开脑洞~
代码用了Python3和requests库,因为时间比较久远,我忘了具体我爬的是哪个区了,我记得应该是【亚洲无码转帖区】,其实当时是想把这个区的torrent都下载下来的,后来想想没必要而且可能硬盘也存不下,就只爬了一下这个区的第一页所有帖子的URL和标题名称。
根据原来的想法是拿到第一页帖子的URL后再遍历列表,进入每个帖子中拿到torrent的URL,然后自动进行下载(自动下载的代码我不会,不过网上应该有相应教程),当第一页的列表遍历完之后再进入第二页,以此类推。
所以我们可以开很多脑洞,就比如说拿我刚才举的搜索的例子来讲,就可以脑洞出这样一个思路:比如我喜欢处女,所以我们搜索“处女”、“破处”这样的关键字,我们还是拿到【亚洲无码转帖区】第一页所有帖子的URL和标题,然后在标题里查找是否有关键字,如果有的话,则进入URL下载torrent,或者将URL保存到另一处列表中集中处理;如果遍历整个列表也没有找到关键字,则进入下一页,以此类推。
这不是教程,代码的教程要靠你们自己去找,爬网页的思路要靠你们自己去琢磨,我这里只是抛砖引玉。
代码没几个,我就直接贴到帖子里吧:
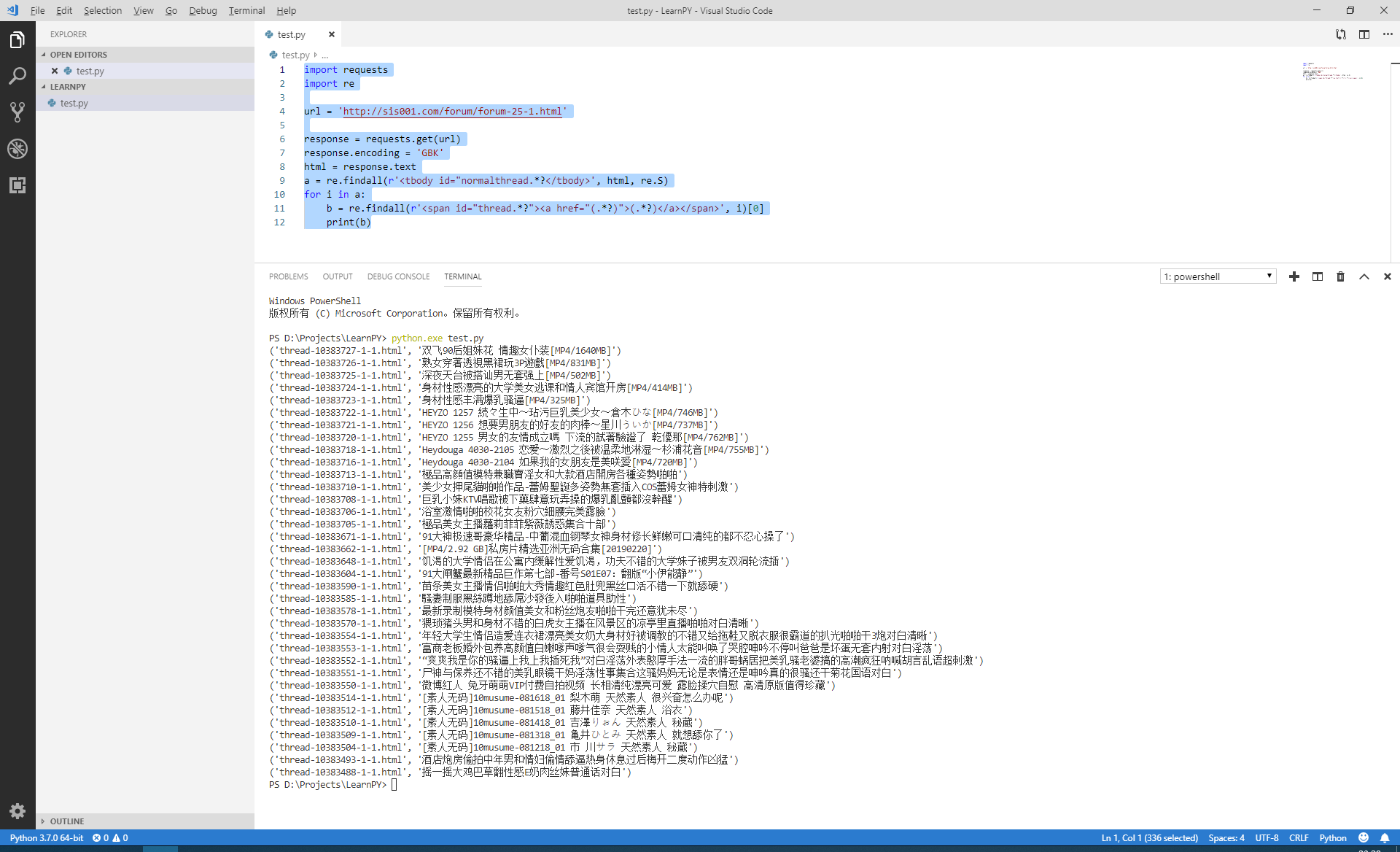
复制内容到剪贴板 代码:import requests
import re
url = 'http://sis001.com/forum/forum-25-1.html'
response = requests.get(url)
response.encoding = 'GBK'
html = response.text
a = re.findall(r'<tbody id="normalthread.*?</tbody>', html, re.S)
for i in a:
b = re.findall(r'<span id="thread.*?"><a href="(.*?)">(.*?)</a></span>', i)[0]
print(b)
运行结果:
|



